Welcome to My Website
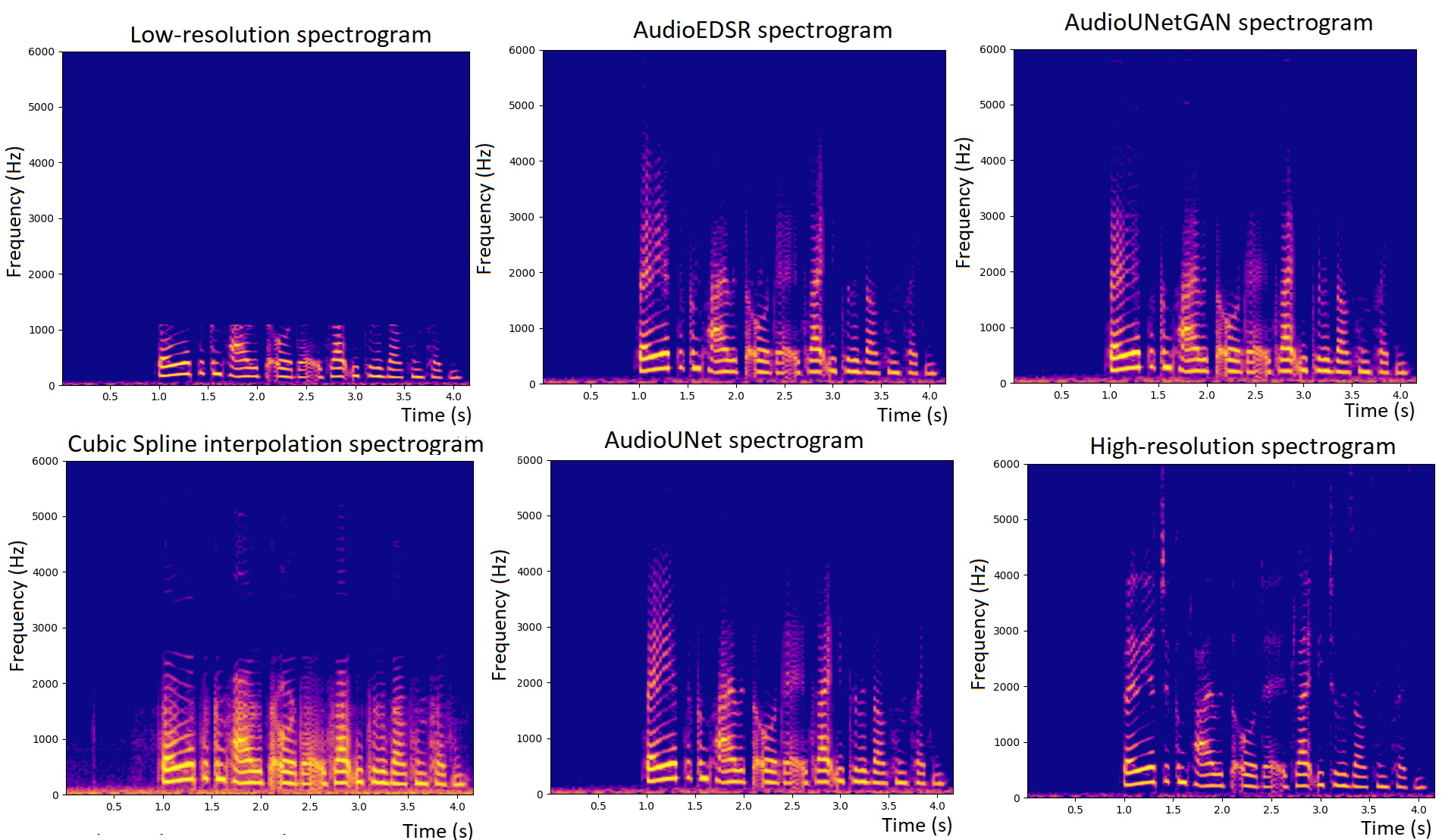
I graduated with a BA (Hons) in Computer Science with Mathematics from The University of Cambridge in July 2021. During my final year, I was awarded the highly commended dissertation prize for my work on Audio Super Resolution, which I have published as a condensed paper. Currently, I am pursuing a PhD at the CVSSP, where my research interests lie in information-theoretic audio analysis and machine learning, including the information-theoretic view of AutoML/MLOPS. Recently, I have been worked on on-device acoustic scene classification, exploring how machine learning models can be designed to run efficiently on resource-constrained devices such as mobile phones and IoT devices.