Papers
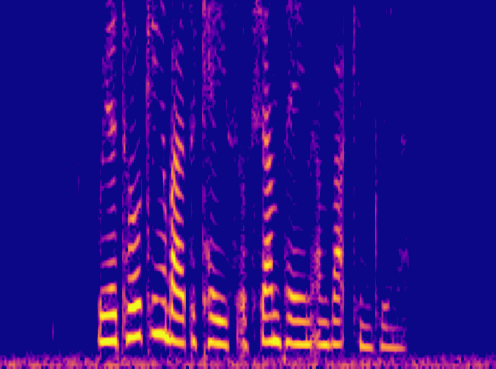
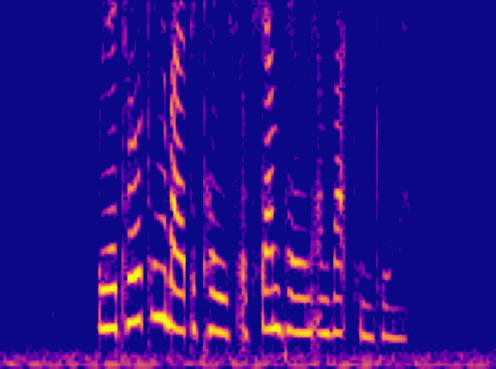
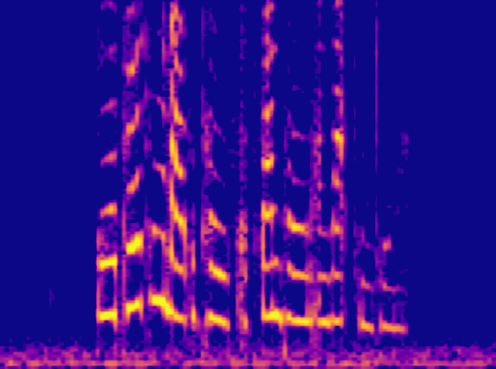
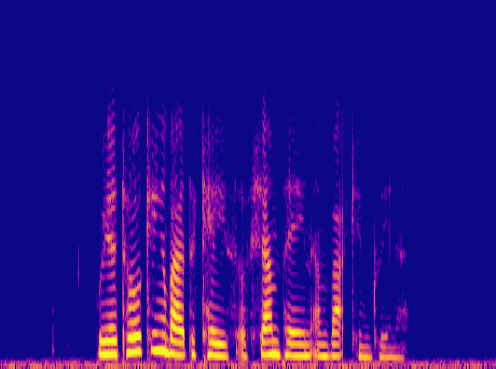
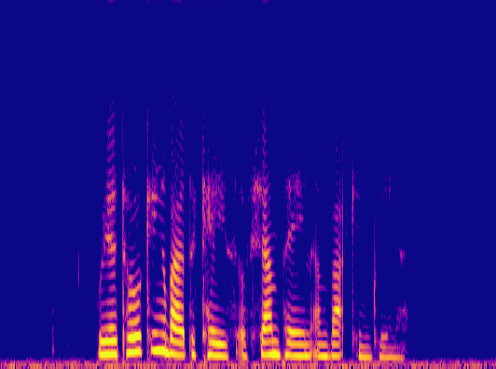
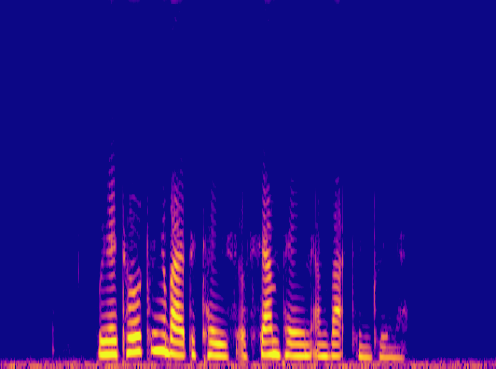
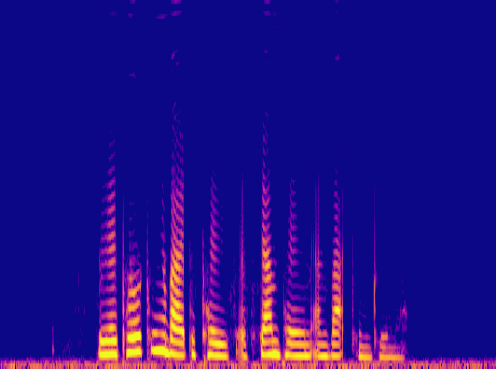
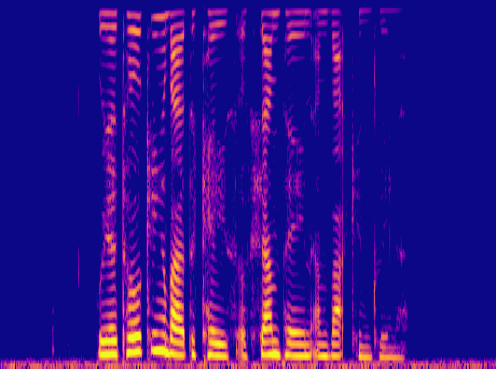
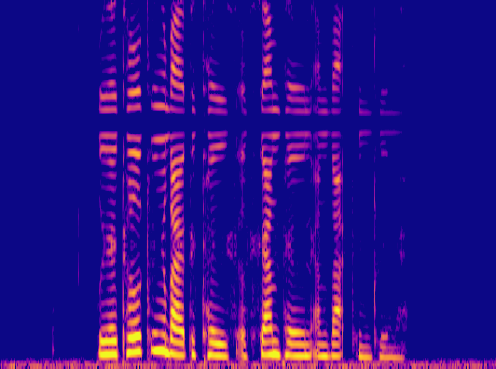
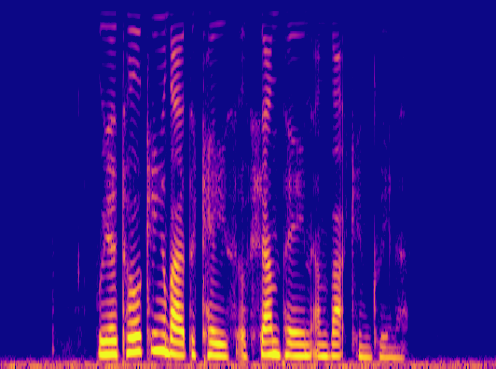
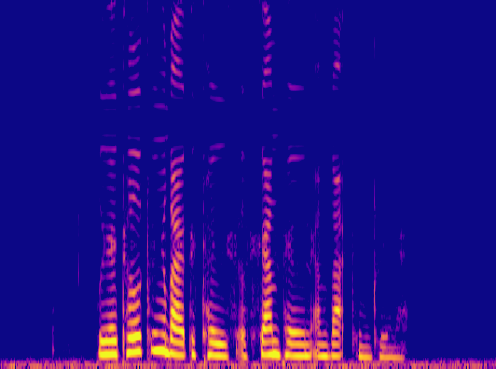
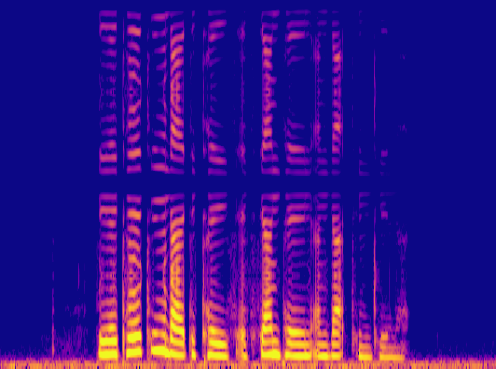
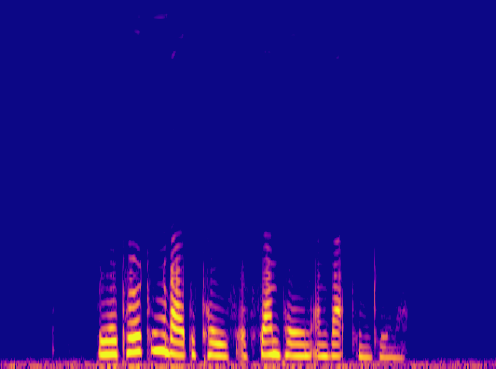
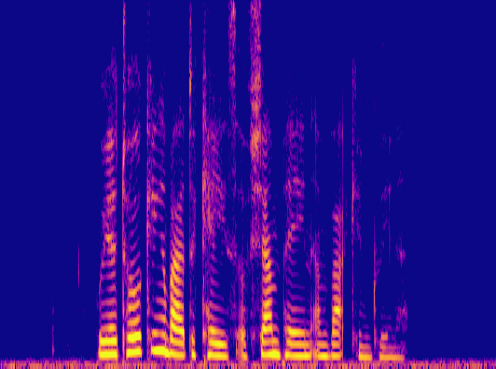
This is a condensed form of my undergraduate dissertation. The aim of the dissertation was to investigate ways to improve the artificial upsampling of low resolution audio. During the course of my studies on this project, I discovered the lack of research into audio artifacting and investigated how its holding the topic back. The projects main achievement was discovering that the unexplored area of pre-upsampling lead to an improved model for lower upsampling cases and the paper focuses on this aspect of the work. I also implemented a GAN to view its effects on training however its performance was heavily let down by the discriminators ability to spot artifacts introduced by the generator.
The Thesis/The paper/The code
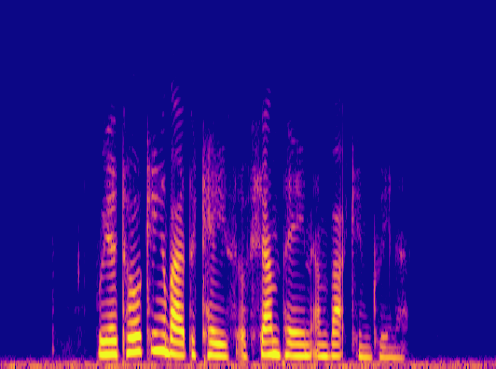
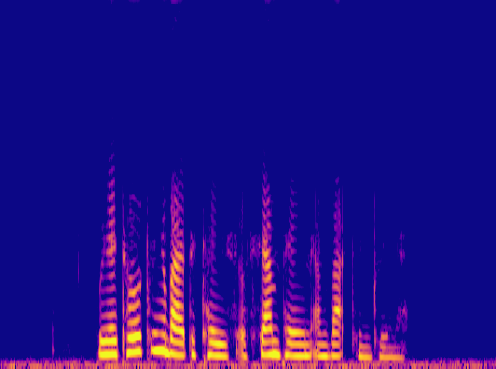
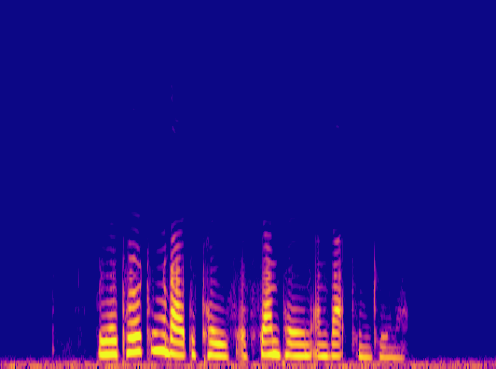
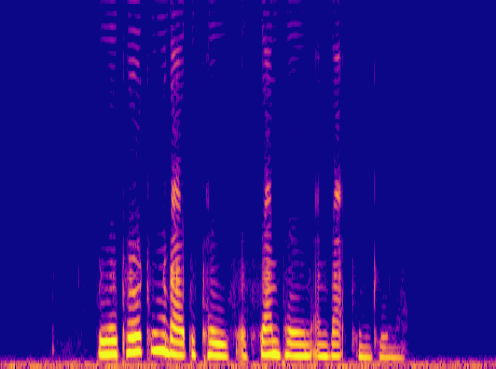
Samples